
重塑和透视表#
pandas 提供了用于操作 Series 和 DataFrame 的方法,以改变数据的表示形式,用于进一步的数据处理或数据汇总。
pivot()和pivot_table()对一个或多个离散类别中的唯一值进行分组。melt()和wide_to_long()将宽格式DataFrame重塑为长格式。get_dummies()和from_dummies()指示变量的转换。explode()将包含列表状值的列转换为单独的行。crosstab()计算多个一维因子数组的交叉表。cut()将连续变量转换为离散、分类值factorize()将一维变量编码为整数标签。
pivot() 和 pivot_table()#

pivot()#
数据通常以所谓的“堆叠”或“记录”格式存储。在“记录”或“宽”格式中,通常每行代表一个主体。而在“堆叠”或“长”格式中,如果有适用情况,每行代表一个主体的一个观察值。
为了对每个唯一变量执行时间序列操作,一种更好的表示方式是让 columns 代表唯一变量,而日期的 index 标识个体观测值。为了将数据重塑成这种形式,我们使用 DataFrame.pivot() 方法(也作为顶层函数 pivot() 实现):
如果省略 values 参数,并且输入 DataFrame 中有多个用于值计算的列(这些列未用作 pivot() 的列或索引输入),则生成的“透视” DataFrame 将具有 hierarchical columns ,其最顶层指示了相应的列值:
然后,您可以从透视后的 DataFrame 中选择子集:
请注意,在底层数据类型均匀的情况下,这会返回底层数据的视图。
备注
pivot() 只能处理由 index 和 columns 指定的唯一行。如果数据包含重复项,请使用 pivot_table() 。
pivot_table()#
虽然 pivot() 提供了通用的透视功能,支持各种数据类型,但 pandas 也提供了 pivot_table() 或 pivot_table() 来进行带数值数据聚合的透视。
pivot_table() 函数可用于创建电子表格样式的透视表。有关一些高级策略,请参阅 cookbook 。
其结果是一个可能在索引或列上具有 DataFrame 的 MultiIndex 。如果未给定 values 列名,则透视表将在列中包含数据的额外层级:
此外,您还可以为 index 和 columns 关键字使用 Grouper 。有关 Grouper 的详细信息,请参阅 Grouping with a Grouper specification 。
添加边距#
将 margins=True 传递给 pivot_table() 将会添加一行和一列,其 All 标签将包含行和列类别上的部分分组聚合:
此外,您还可以调用 DataFrame.stack() 来将透视后的 DataFrame 显示为具有多级索引:
stack() 和 unstack()#
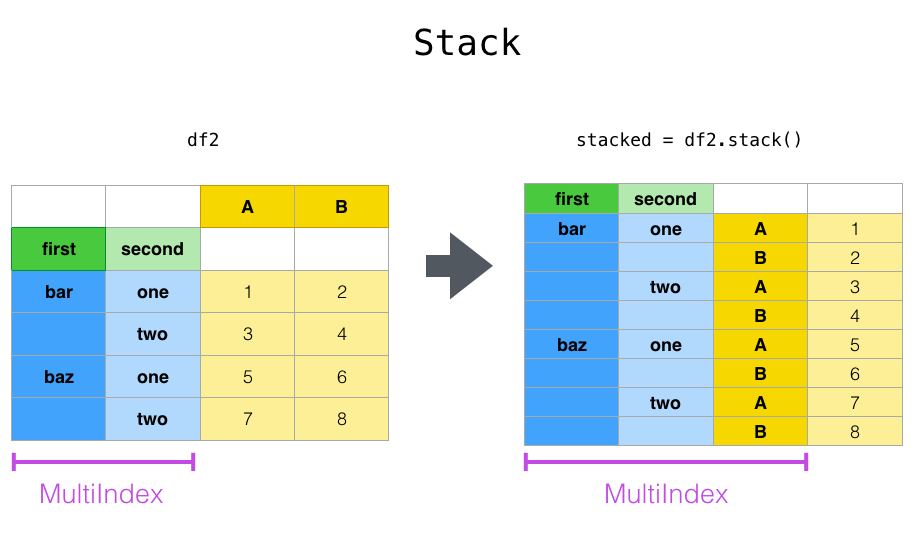
与 pivot() 方法密切相关的是 stack() 和 unstack() 上可用的 Series 和 DataFrame 方法。这些方法旨在与 MultiIndex 对象协同工作(请参阅 hierarchical indexing 一节)。
stack() 函数将“压缩” DataFrame 列中的一个级别,以生成以下两者之一:
DataFrame,在 columns 是MultiIndex的情况下。
如果列具有 MultiIndex ,您可以选择要堆叠的级别。堆叠的级别将成为 columns 上的 MultiIndex 的新的最内层:
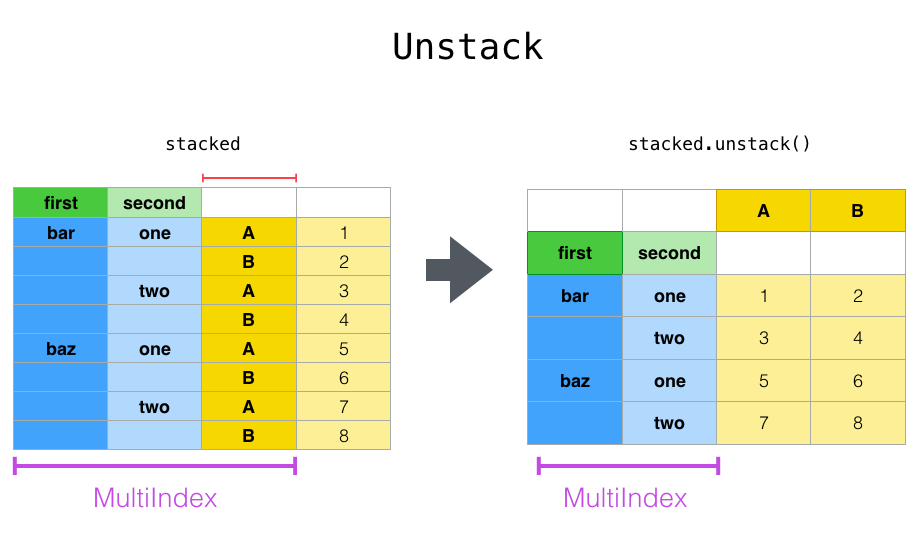
对于具有“堆叠”的 DataFrame 或 Series (其 index 为 MultiIndex ),stack() 的反向操作是 unstack() ,它默认会取消堆叠**最后一个级别**:
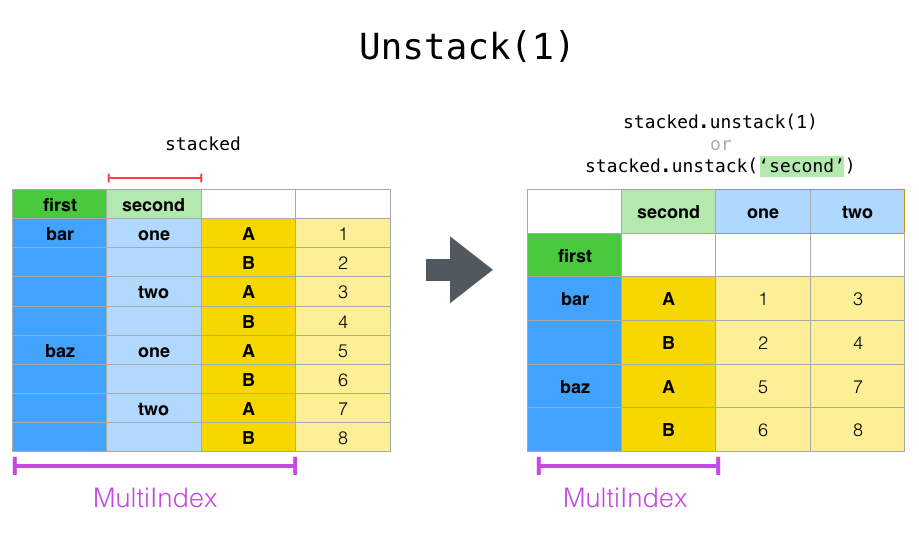
如果索引具有名称,您可以使用级别名称而不是指定级别编号:
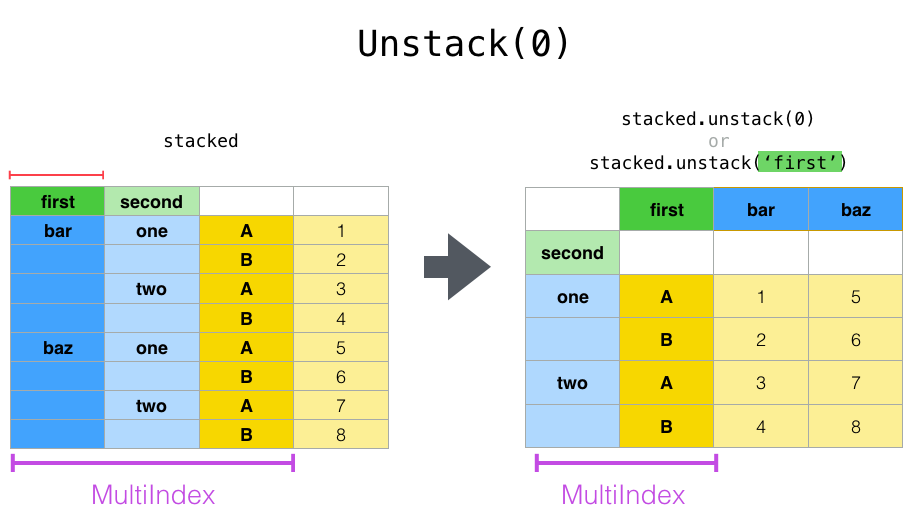
请注意,stack() 和 unstack() 方法会隐式地对涉及的索引级别进行排序。因此,调用 stack() 然后调用 unstack() ,或者反之亦然,都将得到一个已**排序**的原始 DataFrame 或 Series 的副本:
多个级别#
您也可以通过传递一个级别列表来同时堆叠或取消堆叠多个级别,在这种情况下,最终结果就好像列表中的每个级别都单独处理一样。
级别列表可以包含级别名称或级别编号,但不能混合使用。
缺失数据#
取消堆叠可能会导致缺失值,如果子组没有相同的标签集。默认情况下,缺失值将使用该数据类型的默认填充值进行替换。
可以使用 fill_value 参数将缺失值填充为特定值。
melt() 和 wide_to_long()#
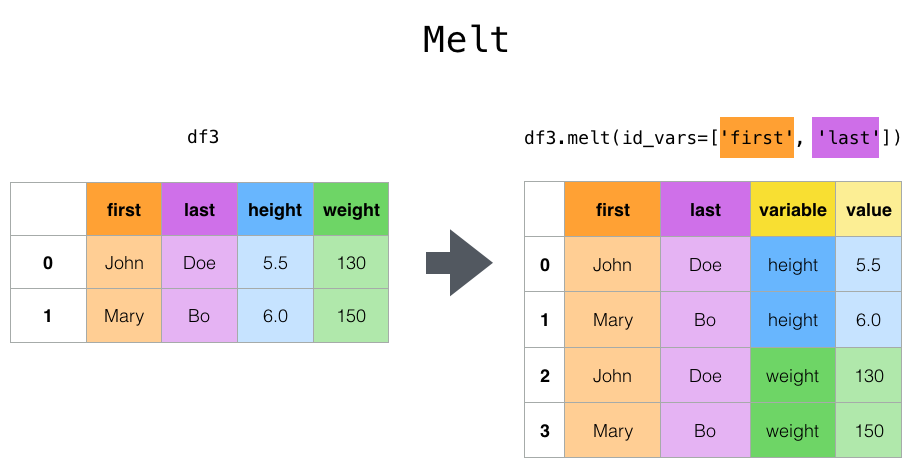
顶层函数 melt() 和相应的 DataFrame.melt() 方法可用于将 DataFrame 整理成一种格式,其中一个或多个列是*标识符变量*,而所有其他列(视为*测量变量*)将被“取消透视”到行轴,只留下两个非标识符列,“variable”和“value”。可以通过提供 var_name 和 value_name 参数来定制这些列的名称。
使用 melt() 转换 DataFrame 时,索引将被忽略。可以通过将 ignore_index=False 参数设置为 False``(默认为 ``True)来保留原始索引值。但 ignore_index=False 会导致索引值重复。
wide_to_long() 类似于 melt() ,但对列匹配提供了更多的自定义选项。
get_dummies() 和 from_dummies()#
要将 Series 的类别变量转换为“虚拟”或“指示”变量,get_dummies() 会创建一个新的 DataFrame ,其中包含唯一变量的列,值为每行指示变量是否存在。
prefix 会为列名添加一个前缀,这对于将结果与原始 DataFrame 合并非常有用:
此函数经常与离散化函数(如 cut() )一起使用:
get_dummies() 也接受 DataFrame 。默认情况下,object、string 或 categorical 类型的列将被编码为虚拟变量,而其他列则保持不变。
指定 columns 关键字将编码任何类型的列。
与 Series 版本一样,您可以为 prefix 和 prefix_sep 传递值。默认情况下,列名用作前缀,_ 用作前缀分隔符。您可以通过 3 种方式指定 prefix 和 prefix_sep:
字符串:为要编码的每个列使用相同的值作为
prefix或prefix_sep。列表:必须与正在编码的列数相同。
字典:将列名映射到前缀。
为了避免在将结果输入统计模型时出现共线性,请指定 drop_first=True。
当列只包含一个级别时,它将在结果中被省略。
可以使用 dtype 参数将值强制转换为其他类型。
在 1.5.0 版本加入.
from_dummies() 将 get_dummies() 的输出转换回类别值的 Series ,从指示值中提取。
虚拟编码数据仅需要包含 k - 1 个类别,在这种情况下,最后一个类别是默认类别。可以使用 default_category 修改默认类别。
explode()#
对于包含嵌套的、类似列表的值的 DataFrame 列,explode() 会将每个类似列表的值转换为一个单独的行。生成的 Index 将根据原始行的索引标签进行重复:
DataFrame.explode 也可以展开 DataFrame 中的列。
Series.explode() 会用缺失值指示符替换空列表,并保留标量条目。
逗号分隔的字符串值可以拆分为列表中的单独值,然后将其拆分为新行。
crosstab()#
使用 crosstab() 计算两个(或多个)因子的交叉表。默认情况下,crosstab() 计算因子的频率表,除非传递了值数组和聚合函数。
传递的任何 Series 都将使用其名称属性,除非指定了交叉表的行或列名称。
如果 crosstab() 只接收两个 Series ,它将提供一个频率表。
crosstab() 也可以汇总到 Categorical 数据。
对于 Categorical 数据,要**包含**所有数据类别,即使实际数据中没有某个类别的实例,请使用 dropna=False。
归一化#
频率表也可以通过 normalize 参数进行标准化,以显示百分比而不是计数:
normalize 也可以按行或按列对值进行标准化:
crosstab() 还可以接受第三个 Series 和一个聚合函数(aggfunc),该函数将应用于由前两个 Series 定义的每个组内的第三个 Series 的值:
添加边距#
margins=True 将添加一行和一列,并带有 All 标签,其中包含行和列类别上的部分组聚合:
cut()#
cut() 函数计算输入数组值的分组,通常用于将连续变量转换为离散或类别变量:
整数 bins 将形成等宽的箱。
有序 bin 边缘的列表将为每个变量分配一个区间。
如果 bins 关键字是 IntervalIndex ,则这些将用于对传递的数据进行分箱。
factorize()#
factorize() 将一维值编码为整数标签。缺失值编码为 -1。
Categorical 将同样地对一维值进行编码,以便进行进一步的类别操作。