
索引和选择数据#
Pandas 对象的轴标签信息有多种用途:
使用已知的指示符标识数据(即提供 元数据),这对于分析、可视化和交互式控制台显示很重要。
启用自动和显式的数据对齐。
允许直观地获取和设置数据集的子集。
在本节中,我们将重点关注最后一点:即如何切片、拆分以及更普遍地获取和设置 Pandas 对象的子集。主要重点将放在 Series 和 DataFrame 上,因为它们在该领域已收到更多的开发关注。
备注
Python 和 NumPy 的索引运算符 [] 和属性运算符 . 为广泛用例下的 Pandas 数据结构提供了快速便捷的访问。这使得交互式工作直观,因为如果你已经知道如何处理 Python 字典和 NumPy 数组,那么需要学习的新东西就很少了。但是,由于要访问的数据类型无法提前知道,直接使用标准运算符存在一些优化限制。对于生产代码,我们建议您利用本章中公开的优化的 Pandas 数据访问方法。
警告
对于设置操作,返回副本还是引用可能取决于上下文。这有时被称为 链式赋值,应该避免。请参阅 Returning a View versus Copy 。
有关 MultiIndex 和更高级的索引文档,请参阅 MultiIndex / Advanced Indexing 。
有关一些高级策略,请参阅 cookbook 。
索引的不同选择#
为了支持更明确的基于位置的索引,对象选择已经添加了许多用户请求的功能。Pandas 现在支持三种类型的多轴索引。
.loc主要基于标签,但也可以与布尔数组一起使用。如果找不到项目,.loc会引发KeyError。允许的输入包括:单个标签,例如
5或'a'``(请注意,``5被解释为索引的 标签。此用法**不是**沿索引的整数位置)。标签列表或数组
['a', 'b', 'c']。标签切片对象 ``’a’:’f’``(请注意,与普通的 Python 切片相反,当存在于索引中时,起始和结束都包含在内!请参阅 Slicing with labels 和 Endpoints are inclusive 。)
布尔数组(任何
NA值将被视为False)。一个
callable函数,带有一个参数(调用它的 Series 或 DataFrame),并返回有效的索引输出(上述内容之一)。行(和列)索引的元组,其元素是上述输入之一。
更多信息请参阅 Selection by Label 。
.iloc主要基于整数位置(从轴的0到length-1),但也可以与布尔数组一起使用。如果请求的索引器超出范围,.iloc会引发IndexError,但*切片*索引器允许超出范围的索引。 (这符合 Python/NumPy 的*切片*语义)。允许的输入包括:整数,例如
5。整数列表或数组
[4, 3, 0]。整数切片对象
1:7。布尔数组(任何
NA值将被视为False)。一个
callable函数,带有一个参数(调用它的 Series 或 DataFrame),并返回有效的索引输出(上述内容之一)。行(和列)索引的元组,其元素是上述输入之一。
更多信息请参阅 Selection by Position 、Advanced Indexing 和 Advanced Hierarchical 。
.loc、.iloc以及[]索引都可以接受callable作为索引器。更多信息请参阅 Selection By Callable 。备注
在应用 callable 之前,会发生将元组键解构为行(和列)索引的操作,因此您无法从 callable 返回一个元组来同时索引行和列。
使用多轴选择从对象中获取值使用以下表示法(以 .loc 为例,但以下内容也适用于 .iloc)。任何轴访问器都可以是空切片 :。规格中遗漏的轴假定为 :,例如 p.loc['a'] 等同于 p.loc['a', :]。
基础知识#
正如在 last section 中介绍数据结构时提到的,使用 []``(对于熟悉在 Python 中实现类行为的人来说,也称为 ``__getitem__)进行索引的主要功能是选择低维切片。下表显示了使用 [] 索引 pandas 对象时返回值的类型:
对象类型 |
选择 |
返回值类型 |
|---|---|---|
Series |
|
标量值 |
DataFrame |
|
与 colname 对应的 |
我们在这里构建一个简单的时间序列数据集,用于演示索引功能:
备注
除非特别说明,否则索引功能没有一个是特定于时间序列的。
因此,如上所述,我们这是使用 [] 进行的最基本索引:
您可以将列列表传递给 [] 以按该顺序选择列。如果 DataFrame 中不包含该列,则会引发异常。也可以以这种方式设置多个列:
您可能会发现这对于对列的子集应用(就地)转换很有用。
警告
pandas 在通过 .loc 设置 Series 和 DataFrame 时会使所有 AXES 对齐。
这**不会**修改 df,因为在值分配之前会进行列对齐。
交换列值的正确方法是使用原始值:
但是,pandas 在通过 .iloc 设置 Series 和 DataFrame 时不会使 AXES 对齐,因为 .iloc 按位置操作。
这会修改 df,因为在值分配之前不会进行列对齐。
属性访问#
您可以直接将 Series 上的索引或 DataFrame 上的列作为属性访问:
警告
只有当索引元素是有效的 Python 标识符时,才能使用此访问,例如,不允许
s.1。有关有效标识符的解释,请参见 here for an explanation of valid identifiers 。如果属性与现有方法名称冲突,则该属性将不可用,例如,不允许
s.min,但s['min']是可能的。同样,如果属性与以下列表中的任何一个冲突,则该属性将不可用:
index、major_axis、minor_axis、items。在所有这些情况下,标准索引仍然有效,例如
s['1']、s['min']和s['index']将访问相应的元素或列。
如果您使用 IPython 环境,您还可以使用选项卡完成来查看这些可访问的属性。
您还可以将 dict 分配给 DataFrame 的某一行:
您可以使用属性访问来修改 Series 的现有元素或 DataFrame 的列,但请小心;如果您尝试使用属性访问创建新列,它会创建一个新属性而不是新列,并将引发 UserWarning:
切片范围#
沿任意轴切片的最健壮、最一致的方法在描述 .iloc 方法的 Selection by Position 部分进行了介绍。现在,我们解释使用 [] 运算符进行切片的语义。
对于 Series,语法与 ndarray 完全相同,返回值的切片和相应的标签:
请注意,设置也有效:
对于 DataFrame,[] 内的切片**会切片行**。这主要是作为一种便利提供的,因为它是一种非常常见的操作。
按标签选择#
警告
对于设置操作,返回的是副本还是引用可能取决于上下文。这有时被称为“链式赋值”,应避免使用。请参阅 Returning a View versus Copy 。
警告
当您提供的切片器与索引类型不兼容(或不可转换)时,
.loc会表现严格。例如,在DatetimeIndex中使用整数。这些将引发TypeError。
切片中的类字符串可以转换为索引的类型,并导致自然切片。
pandas 提供了一套方法来实现**纯粹基于标签的索引**。这是一个严格的包含协议。所请求的每个标签都必须在索引中,否则将引发 KeyError。在切片时,开始边界**和**结束边界(如果存在于索引中)都**包含**在内。整数是有效的标签,但它们指的是标签**而不是**位置。
.loc 属性是主要的访问方法。以下是有效的输入:
单个标签,例如
5或'a'``(请注意,``5被解释为索引的 标签。此用法**不是**沿索引的整数位置)。标签列表或数组
['a', 'b', 'c']。一个带有标签
'a':'f'的 slice 对象 (请注意,与通常的 Python slice 不同,当标签存在于索引中时,**起始和结束**都包含在内!参见 Slicing with labels 。一个布尔数组。
一个
callable,参见 Selection By Callable 。
请注意,设置也有效:
对于 DataFrame:
通过标签 slice 访问:
通过标签获取横截面 (等同于 df.xs('a')):
通过布尔数组获取值:
布尔数组中的 NA 值传播为 False:
明确地获取一个值:
使用标签进行切片#
当使用带 slice 的 .loc 时,如果起始和结束标签都存在于索引中,则返回位于两者之间(包括它们)的元素:
如果至少一个标签缺失,但索引已排序,并且可以与起始和结束标签进行比较,则切片仍按预期工作,通过选择*排名*在两者之间的标签来工作:
但是,如果至少一个标签缺失*且*索引未排序,将引发错误 (因为否则的操作计算成本过高,并且对于混合类型的索引也可能模棱两可)。例如,在上面的示例中,s.loc[1:6] 将引发 KeyError。
有关此行为的原理,请参见 Endpoints are inclusive 。
另外,如果索引具有重复标签*且*起始或结束标签重复,将引发错误。例如,在上面的示例中,s.loc[2:5] 将引发 KeyError。
有关重复标签的更多信息,请参见 Duplicate Labels 。
按位置选择#
警告
对于设置操作,返回的是副本还是引用可能取决于上下文。这有时被称为“链式赋值”,应避免使用。请参阅 Returning a View versus Copy 。
pandas 提供了一系列方法来实现**纯粹基于整数的索引**。其语义紧密遵循 Python 和 NumPy 的切片。这些是``0-based``索引。切片时,起始边界*包含*在内,而上边界*不包含*在内。尝试使用非整数,即使是**有效的**标签,也会引发 IndexError。
.iloc 属性是主要的访问方法。以下是有效的输入:
整数,例如
5。整数列表或数组
[4, 3, 0]。整数切片对象
1:7。一个布尔数组。
一个
callable,参见 Selection By Callable 。行 (和列) 索引的元组,其元素是上述类型之一。
请注意,设置也有效:
对于 DataFrame:
通过整数切片选择:
通过整数列表选择:
通过整数位置获取横截面 (等同于 df.xs(1)):
超出范围的切片索引会像 Python/NumPy 一样被优雅地处理。
请注意,使用超出边界的切片可能导致空轴 (例如,返回一个空的 DataFrame)。
超出边界的单个索引器将引发 IndexError。超出边界的索引器列表将引发 IndexError。
通过 callable 进行选择#
.loc, .iloc, 以及 [] 索引都可以接受一个 callable 作为索引器。该 callable 必须是一个带有单个参数 (调用的 Series 或 DataFrame) 的函数,该函数返回有效的索引输出。
备注
对于 .iloc 索引,从 callable 返回一个元组是不支持的,因为行和列索引的元组解构发生在应用 callable*之前*。
您可以在 Series 中使用 callable 索引。
使用这些方法/索引器,您可以链接数据选择操作,而无需使用临时变量。
组合位置和标签索引#
如果您想在 ‘A’ 列中获取第 0 个和第 2 个元素,您可以这样做:
也可以使用 .iloc 来表达,通过显式地获取索引器的位置,并使用*位置*索引来选择内容。
要获取*多个*索引器,请使用 .get_indexer:
重新索引#
实现选择可能未找到的元素的惯用方法是通过 .reindex()。另请参见 reindexing 部分。
或者,如果您只想选择*有效*的键,以下方法是惯用的且高效的;它保证会保留所选内容的 dtype。
具有重复索引的 .reindex() 会引发错误:
通常,您可以将所需的标签与当前轴进行交集,然后重新索引。
但是,如果您的结果索引是重复的,这*仍然*会引发错误。
选择随机样本#
使用 sample() 方法从 Series 或 DataFrame 中随机选择行或列。该方法默认采样行,并接受要返回的行/列数,或行的比例。
默认情况下,sample 会至多返回每行一次,但您也可以使用 replace 选项进行有放回抽样:
默认情况下,每行被选中的概率相等,但如果您希望行具有不同的概率,则可以将采样权重作为 weights 传递给 sample 函数。这些权重可以是列表、NumPy 数组或 Series,但它们的长度必须与您正在采样的对象相同。缺失值将被视为权重为零,不允许有 inf 值。如果权重不等于 1,它们将被重新归一化(将所有权重除以权重总和)。例如:
当应用于 DataFrame 时,您可以将 DataFrame 的某一列用作采样权重(前提是您正在采样行而不是列),只需将列名作为字符串传递即可。
sample 还允许用户使用 axis 参数采样列而不是行。
最后,您还可以使用 random_state 参数为 sample 的随机数生成器设置一个种子,它可以接受整数(作为种子)或 NumPy RandomState 对象。
带扩充的赋值#
.loc/[] 操作在为某个轴设置不存在的键时可以执行扩充。
在 Series 的情况下,这实际上是一个追加操作。
DataFrame 可以通过 .loc 在任何一个轴上进行扩充。
这类似于 DataFrame 上的 append 操作。
快速标量值获取和设置#
由于 [] 索引必须处理许多情况(单标签访问、切片、布尔索引等),它会有一点开销来确定您要查找的内容。如果您只想访问标量值,最快的方法是使用 at 和 iat 方法,它们在所有数据结构上都实现了。
与 loc 类似,at 提供基于**标签**的标量查找,而 iat 提供基于**整数**的查找,这与 iloc 类似。
您也可以使用这些相同的索引器进行设置。
如果索引器不存在,at 可能会像上面那样就地扩充对象。
布尔索引#
另一个常见的操作是使用布尔向量来过滤数据。运算符是:| 表示 or,& 表示 and,~ 表示 not。这些**必须**使用括号分组,因为默认情况下,Python 会将表达式如 df['A'] > 2 & df['B'] < 3 评估为 df['A'] > (2 & df['B']) < 3,而期望的求值顺序是 (df['A'] > 2) & (df['B'] < 3)。
使用布尔向量索引 Series 的工作方式与 NumPy ndarray 完全相同:
您可以使用与 DataFrame 索引长度相同的布尔向量(例如,从 DataFrame 的某一列派生的内容)从 DataFrame 中选择行:
列表推导式和 Series 的 map 方法也可以用于生成更复杂的条件:
通过选择方法 Selection by Label 、Selection by Position 和 Advanced Indexing ,您可以使用布尔向量与其他索引表达式结合来选择多个轴。
警告
iloc 支持两种布尔索引。如果索引器是布尔 Series,则会引发错误。例如,在以下示例中,df.iloc[s.values, 1] 是可以的。布尔索引器是一个数组。但 df.iloc[s, 1] 会引发 ValueError。
使用 isin 进行索引#
考虑 Series 的 isin() 方法,它返回一个布尔向量,当 Series 元素存在于传递的列表中时,该向量为 true。这允许您选择其中一个或多个列具有您想要的值的行:
Index 对象也可用相同的方法,当您不知道所查找的标签中哪些实际上存在时,该方法很有用:
此外,MultiIndex 允许选择一个单独的级别以用于成员资格检查:
DataFrame 还有一个 isin() 方法。 调用 isin 时,将一组值作为数组或字典传入。 如果值是数组,isin 会返回一个布尔型的 DataFrame,其形状与原始 DataFrame 相同,其中对应元素存在于值序列中的位置为 True。
通常,您会希望将某些值与某些列进行匹配。 只需将值设为 dict,其中键是列名,值是您要检查的项列表。
要返回 DataFrame 中值*不*在原始 DataFrame 中的布尔型 DataFrame,请使用 ~ 运算符:
将 DataFrame 的 isin 与 any() 和 all() 方法结合使用,可以快速选择满足给定标准的 DataFrame 子集。 要选择一行中每列都满足自身标准的行:
where() 方法和掩码#
使用布尔向量从 Series 中选择值通常会返回数据的子集。 要确保选择的输出具有与原始数据相同的形状,可以使用 Series 和 DataFrame 中的 where 方法。
仅返回选定的行:
返回一个与原始 Series 形状相同的 Series:
使用布尔条件从 DataFrame 中选择值现在也保留了输入数据的形状。 where 在底层用作实现。 下面的代码等同于 df.where(df < 0)。
此外,where 接受一个可选的 other 参数,用于在返回的副本中替换条件为 False 的值。
您可能希望根据某些布尔条件设置值。 可以直观地像这样完成:
where 返回数据的修改副本。
备注
DataFrame.where() 的签名与 numpy.where() 不同。 大致上 df1.where(m, df2) 等同于 np.where(m, df1, df2)。
对齐
此外,where 会对齐输入的布尔条件(ndarray 或 DataFrame),因此可以进行部分选择和设置。 这类似于使用 .loc 进行部分设置(但作用于内容而不是轴标签)。
Where 还可以接受 axis 和 level 参数来在执行 where 时对齐输入。
这等同于(但比以下代码更快):
where 可以接受一个可调用对象作为条件和 other 参数。 该函数必须带有一个参数(调用它的 Series 或 DataFrame),并返回有效的输出作为条件和 other 参数。
掩码#
mask() 是 where 的逆布尔运算。
使用 numpy() 条件设置并扩展#
where() 的替代方法是使用 numpy.where() 。 结合设置新列,您可以利用它根据条件确定值的 DataFrame 进行扩展。
假设您要在下面的 DataFrame 中从两个选择中进行选择。 您想在第二列中是“Z”时将新列“color”设置为“green”。 您可以这样做:
如果您有多个条件,可以使用 numpy.select() 来实现。 假设有三个条件对应三种颜色选择,以及第四种颜色作为备选,您可以这样做。
query() 方法#
DataFrame 对象有一个 query() 方法,允许使用表达式进行选择。
您可以获取 DataFrame 中列 b 的值介于列 a 和 c 的值之间的部分。 例如:
执行相同的操作,但如果不存在名为 a 的列,则回退到名为 index 的索引。
如果您不想或无法命名您的索引,可以在查询表达式中使用名称 index:
备注
如果您的索引名称与列名重叠,则列名将具有优先权。 例如,
您仍然可以通过使用特殊标识符 ‘index’ 在查询表达式中使用索引:
如果您因为某种原因有一列名为 index,那么您也可以将索引称为 ilevel_0,但此时您应该考虑将您的列重命名为不那么含糊不清的名称。
MultiIndex query() 语法#
你也可以把具有 MultiIndex 的 DataFrame 的层级当作该框架的列来使用:
如果 MultiIndex 的层级是未命名的,你可以使用特殊名称来引用它们:
约定俗成是 ilevel_0,对于索引的第 0 层来说,它表示“索引层 0”。
query() 的使用场景#
query() 的一个使用场景是当你有一个 DataFrame 对象集合,它们共享一部分共同的列名(或索引层/名称)。你可以将相同的查询传递给这两个框架,而*无需*指定你感兴趣的框架。
query() Python 与 Pandas 语法对比#
完整的类 NumPy 语法:
通过移除括号,稍微更好看一些(比较运算符的结合性比 & 和 | 更强):
使用英文而不是符号:
非常接近你在纸上书写的方式:
in 和 not in 运算符#
query() 也支持 Python 的 in 和 not in 比较运算符的特殊用途,为调用 Series 或 DataFrame 的 isin 方法提供了一种简洁的语法。
你可以将它与其他表达式结合起来,进行非常简洁的查询:
备注
请注意,in 和 not in 是在 Python 中求值的,因为 numexpr 没有等效的操作。但是,只有 in/not in **表达式本身**是在纯 Python 中求值的。例如,在表达式中
df.query('a in b + c + d')
(b + c + d) 由 numexpr 求值,然后 in 操作在纯 Python 中求值。总的来说,任何可以通过 numexpr 求值得出的操作都会被执行。
对 list 对象使用 == 运算符的特殊用法#
使用 ==/!= 将一个值的 list 与一列进行比较,其工作方式类似于 in/not in。
布尔运算符#
你可以使用 not 关键字或 ~ 运算符来否定布尔表达式。
当然,表达式也可以任意复杂:
query() 的性能#
使用 numexpr 的 DataFrame.query() 对于大型框架比 Python 稍微快一些。
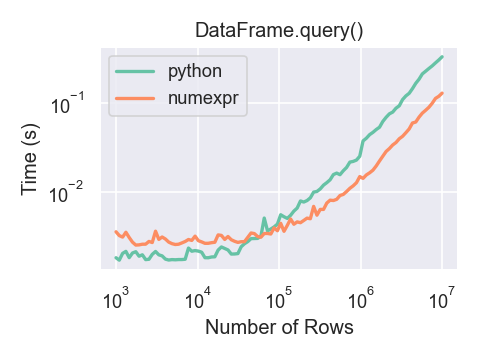
只有当你的框架包含超过大约 100,000 行时,你才会看到使用 numexpr 引擎配合 DataFrame.query() 带来的性能优势。
这张图表是通过一个包含 3 列的 DataFrame 创建的,每一列都包含使用 numpy.random.randn() 生成的浮点值。
重复数据#
如果你想识别并删除 DataFrame 中的重复行,有两个方法可以帮助你:duplicated 和 drop_duplicates。每个方法都接受一个参数,用于指定用于识别重复行的列。
duplicated返回一个布尔向量,其长度与行数相同,指示某行是否重复。drop_duplicates会删除重复的行。
默认情况下,重复集中的第一次出现的行被视为唯一,但每个方法都有一个 keep 参数来指定要保留的目标。
keep='first'(默认): 标记/删除重复项,除了第一次出现。keep='last': 标记/删除重复项,除了最后一次出现。keep=False: 标记/删除所有重复项。
此外,你可以传递一个列的列表来识别重复项。
要按索引值删除重复项,请使用 Index.duplicated 然后执行切片。对于 keep 参数,也有一套相同的选项可用。
类似字典的 get() 方法#
Series 或 DataFrame 都有一个 get 方法,可以返回一个默认值。
按索引/列标签查找值#
有时你希望根据一系列行标签和列标签提取一组值,这可以通过 pandas.factorize 和 NumPy 索引来实现。例如:
以前,这可以通过专门的 DataFrame.lookup 方法来实现,该方法在版本 1.2.0 中被弃用,并在版本 2.0.0 中被移除。
索引对象#
Pandas 的 Index 类及其子类可以被视为实现了*有序多重集*。允许重复。
Index 还提供了查找、数据对齐和重新索引所必需的基础设施。直接创建 Index 的最简单方法是将 list 或其他序列传递给 Index :
或使用数字:
如果未指定 dtype,Index 会尝试从数据推断 dtype。在实例化 Index 时,也可以指定显式的 dtype:
也可以传递一个 name 来存储在索引中:
如果设置了名称,它将在控制台显示:
设置元数据#
索引是“大部分不可变的”,但可以设置和更改它们的 name 属性。您可以使用 rename、set_names 直接设置这些属性,默认情况下它们会返回一个副本。
有关 MultiIndexes 的用法,请参见 Advanced Indexing 。
set_names、set_levels 和 set_codes 也接受一个可选的 level 参数
对 Index 对象执行集合运算#
两个主要操作是 union 和 intersection。差集通过 .difference() 方法提供。
还有一个 symmetric_difference 操作,它返回出现在 idx1 或 idx2 中,但不同时出现在两者中的元素。这等同于由 idx1.difference(idx2).union(idx2.difference(idx1)) 创建的索引,并丢弃重复项。
备注
集合运算的结果索引将按升序排序。
在对具有不同 dtype 的索引执行 Index.union() 时,必须将索引强制转换为通用 dtype。通常(但不总是)是 object dtype。例外情况是当对整数和浮点数据执行联合运算时。在这种情况下,整数值将被转换为浮点数。
缺失值#
重要
尽管 Index 可以包含缺失值 (NaN),但如果您不希望出现任何意外结果,应避免使用它们。例如,某些操作会隐式排除缺失值。
Index.fillna 使用指定的标量值填充缺失值。
设置/重置索引#
有时您会在创建 DataFrame 后加载或创建一个数据集,并希望添加一个索引。有几种不同的方法。
设置索引#
DataFrame 有一个 set_index() 方法,该方法接受列名(对于常规 Index)或列名列表(对于 MultiIndex)。要创建一个新的、重新索引的 DataFrame:
append 关键字选项允许您保留现有索引并将给定的列追加到 MultiIndex:
set_index 中的其他选项允许您不删除索引列。
重置索引#
为了方便起见,DataFrame 上有一个新的函数 reset_index() ,它将索引值移入 DataFrame 的列并将一个简单的整数索引设置为新的索引。这是 set_index() 的逆操作。
输出更类似于 SQL 表或记录数组。从索引派生的列名是存储在 names 属性中的那些名称。
您可以使用 level 关键字仅删除索引的一部分:
reset_index 接受一个可选参数 drop,如果设置为 true,则直接丢弃索引,而不是将索引值放入 DataFrame 的列中。
添加临时索引#
您可以将自定义索引分配给 index 属性:
返回视图还是副本#
警告
Copy-on-Write 将成为 pandas 3.0 中的新默认设置。这意味着链式索引将永远不起作用。因此,将不再需要 SettingWithCopyWarning。有关更多背景信息,请参见 this section 。我们建议在 pandas 3.0 之前就启用写时复制,以利用以下改进:
`
pd.options.mode.copy_on_write = True
`
即使在 3.0 版本可用之前。
在设置 pandas 对象的值时,必须小心避免所谓的“链式索引”。下面是一个示例。
比较这两种访问方法:
这两者都产生相同的结果,那么应该使用哪种呢?理解这些操作的顺序以及为什么方法 2 (.loc) 比方法 1 (链式 []) 更受青睐是很有启发性的。
dfmi['one'] 选择列的第一个级别并返回一个单索引的 DataFrame。然后,另一个 Python 操作 dfmi_with_one['second'] 选择由 'second' 索引的 Series。这由变量 dfmi_with_one 指示,因为 pandas 将这些操作视为独立事件。例如,对 __getitem__ 的独立调用,因此它必须将它们视为线性操作,它们一个接一个地发生。
将此与 df.loc[:,('one','second')] 进行对比,它会将一个嵌套元组 (slice(None),('one','second')) 传递给对 __getitem__ 的一次调用。这使得 pandas 可以将其作为一个整体来处理。此外,这种操作顺序*可以*显著提高速度,并允许您同时索引*两个*轴。
为什么在链式索引时赋值会失败?#
警告
Copy-on-Write 将成为 pandas 3.0 中的新默认设置。这意味着链式索引将永远无法正常工作。因此,将不再需要 SettingWithCopyWarning。有关更多背景信息,请参阅 this section 。我们建议启用 Copy-on-Write 以利用以下方面的改进:
`
pd.options.mode.copy_on_write = True
`
即使在 3.0 版本可用之前。
前面一节中的问题仅仅是一个性能问题。那么 SettingWithCopy 警告是怎么回事?我们**通常**不会随意发出警告,仅仅因为您做的事情可能会花费几毫秒!
但事实证明,为链式索引的结果赋值具有内在的不可预测性。要理解这一点,请考虑 Python 解释器如何执行此代码:
dfmi.loc[:, ('one', 'second')] = value
# becomes
dfmi.loc.__setitem__((slice(None), ('one', 'second')), value)
但这段代码的处理方式不同:
dfmi['one']['second'] = value
# becomes
dfmi.__getitem__('one').__setitem__('second', value)
看到其中的 __getitem__ 了吗?在简单的情况下,很难预测它会返回一个视图还是一个副本(这取决于数组的内存布局,pandas 对此不作任何保证),因此 __setitem__ 将修改 dfmi 还是一个立即被丢弃的临时对象。**这**就是 SettingWithCopy 警告您的内容!
备注
您可能想知道是否应该担心第一个示例中的 loc 属性。但 dfmi.loc 保证是 dfmi 本身,只是索引行为有所修改,因此 dfmi.loc.__getitem__ / dfmi.loc.__setitem__ 直接在 dfmi 上操作。当然,dfmi.loc.__getitem__(idx) 可能是 dfmi 的视图或副本。
有时,即使没有明显的链式索引,也会出现 SettingWithCopy 警告。**这些**正是 SettingWithCopy 旨在捕获的 bug!pandas 可能在警告您执行了以下操作:
def do_something(df):
foo = df[['bar', 'baz']] # Is foo a view? A copy? Nobody knows!
# ... many lines here ...
# We don't know whether this will modify df or not!
foo['quux'] = value
return foo
糟糕!
求值顺序很重要#
警告
Copy-on-Write 将成为 pandas 3.0 中的新默认设置。这意味着链式索引将永远无法正常工作。因此,将不再需要 SettingWithCopyWarning。有关更多背景信息,请参阅 this section 。我们建议启用 Copy-on-Write 以利用以下方面的改进:
`
pd.options.mode.copy_on_write = True
`
即使在 3.0 版本可用之前。
当您使用链式索引时,索引操作的顺序和类型部分决定了结果是原始对象的切片还是切片的副本。
pandas 出现 SettingWithCopyWarning 是因为将切片副本赋值通常不是故意的,而是由于链式索引返回了副本而不是预期的切片而导致的错误。
如果您希望 pandas 对链式索引表达式赋值更或不那么信任,您可以将 option mode.chained_assignment 设置为以下值之一:
'warn'``(默认值)表示会打印 ``SettingWithCopyWarning。'raise'表示 pandas 将引发一个SettingWithCopyError,您需要处理它。None将完全抑制警告。
然而,这实际上是对一个副本进行操作,因此将无效。
在混合数据类型的框架中也可能出现链式赋值。
备注
这些赋值规则适用于所有的 .loc/.iloc。
以下是使用 .loc 的推荐访问方法,用于多个项目(使用 mask)和一个固定索引的单个项目:
以下操作有时*可以*成功,但不能保证,因此应避免:
最后,以下示例将完全**无效**,因此应避免:
警告
链式赋值警告/异常旨在告知用户可能存在的无效赋值。可能存在误报;即链式赋值被意外报告的情况。