
与电子表格的比较#
由于许多潜在的 pandas 用户都熟悉 Excel 等电子表格程序,因此本页旨在举例说明如何使用 pandas 执行各种电子表格操作。本页将使用 Excel 的术语并链接到其文档,但大部分内容在 Google Sheets 、LibreOffice Calc 、Apple Numbers 以及其他 Excel 兼容的电子表格软件中也相同/相似。
如果你是 pandas 新手,你可能想先阅读 10 Minutes to pandas 来熟悉该库。
按照惯例,我们像这样导入 pandas 和 NumPy:
数据结构#
通用术语翻译#
pandas |
Excel |
|---|---|
|
工作表 |
|
column |
|
行标题 |
row |
row |
|
空单元格 |
DataFrame#
pandas 中的 DataFrame 类似于 Excel 工作表。虽然 Excel 工作簿可以包含多个工作表,但 pandas DataFrame 是独立存在的。
Series#
Series 是表示 DataFrame 一列的数据结构。处理 Series 类似于引用电子表格的列。
Index#
每个 DataFrame 和 Series 都有一个 Index,它是数据*行*上的标签。在 pandas 中,如果未指定索引,则默认使用 RangeIndex (第一行 = 0,第二行 = 1,依此类推),这类似于电子表格中的行标题/编号。
在 pandas 中,可以将索引设置为一个(或多个)唯一值,这相当于有一个用作工作表中行标识符的列。与大多数电子表格不同,这些 Index 值实际上可用于引用行。(请注意,this can be done in Excel with structured references 。)例如,在电子表格中,您会引用第一行为 A1:Z1,而在 pandas 中,您可以使用 populations.loc['Chicago']。
索引值也是持久的,所以如果你重新排序``DataFrame``中的行,特定行的标签也不会改变。
有关如何有效使用``Index``的更多信息,请参阅 indexing documentation 。
副本 vs. 原地操作#
大多数 pandas 操作会返回 Series/DataFrame 的副本。要使更改“生效”,您需要将其赋给一个新变量:
sorted_df = df.sort_values("col1")
或者覆盖原始变量:
df = df.sort_values("col1")
备注
您会看到一些方法提供了 inplace=True 或 copy=False 关键字参数:
df.replace(5, inplace=True)
目前正在积极讨论弃用和删除大多数方法的 inplace 和 copy``(例如,``dropna),只保留一小部分方法(包括 replace)。在 Copy-on-Write 的上下文中,这两个关键字将不再需要。该提案可以在 here 找到。
数据输入/输出#
从值构建 DataFrame#
在电子表格中,values can be typed directly into cells 。
pandas DataFrame 可以通过多种方式构建,但对于少量值,通常将其指定为 Python 字典会很方便,其中键是列名,值是数据。
读取外部数据#
Both Excel and pandas can import data from various sources in various formats.
CSV#
让我们从 pandas 测试中加载并显示 tips 数据集,这是一个 CSV 文件。在 Excel 中,你需要下载然后 open the CSV 。在 pandas 中,你将 CSV 文件的 URL 或本地路径传递给 read_csv() :
与 Excel’s Text Import Wizard 类似,read_csv 可以接受许多参数来指定如何解析数据。例如,如果数据是制表符分隔的,并且没有列名,那么 pandas 命令将是:
tips = pd.read_csv("tips.csv", sep="\t", header=None)
# alternatively, read_table is an alias to read_csv with tab delimiter
tips = pd.read_table("tips.csv", header=None)
Excel 文件#
Excel 通过双击或使用 various Excel file formats 打开 the Open menu 。在 pandas 中,你使用 special methods for reading and writing from/to Excel files 。
让我们首先 create a new Excel file 基于上面示例中的 tips 数据框:
tips.to_excel("./tips.xlsx")
如果你想稍后访问 tips.xlsx 文件中的数据,可以使用以下方法将其读入你的模块:
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
你刚刚使用 pandas 读取了一个 Excel 文件!
限制输出#
电子表格程序一次只显示一屏幕的数据,然后允许你滚动,所以实际上没有必要限制输出。在 pandas 中,你需要仔细考虑如何控制 DataFrame 的显示。
默认情况下,pandas 会截断大型 DataFrame 的输出,只显示第一行和最后一行。这可以通过 changing the pandas options 或使用 DataFrame.head() 或 DataFrame.tail() 来覆盖。
导出数据#
默认情况下,桌面电子表格软件会将其保存为相应的[文件格式](https://support.microsoft.com/en-us/office/save-a-workbook-in-another-file-format-6a16c862-4a36-48f9-a300-c2ca0065286e)(.xlsx, .ods 等)。但是,你也可以 save to other file formats 。
pandas can create Excel files 、CSV 或 a number of other formats 。
数据操作#
列上的操作#
在电子表格中,formulas 通常在单个单元格中创建,然后 dragged 到其他单元格以计算其他列。在 pandas 中,你可以直接对整个列执行操作。
pandas 通过指定单个 Series 在 DataFrame 中提供矢量化操作。也可以用同样的方式分配新列。 DataFrame.drop() 方法会从 DataFrame 中删除一列。
请注意,我们不必逐个单元格地告诉它执行减法运算——pandas 为我们处理了这些。有关 how to create new columns derived from existing columns 的信息。
过滤#
In Excel, filtering is done through a graphical menu.
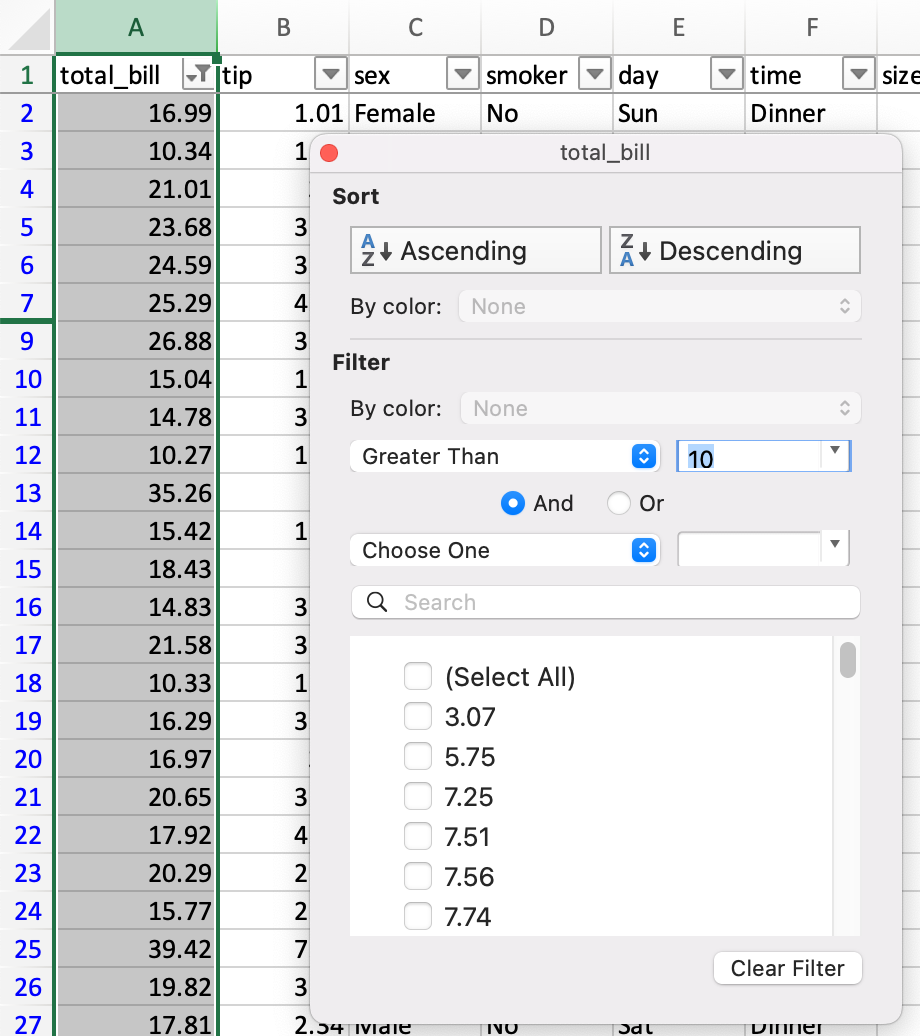
DataFrame 可以通过多种方式进行过滤;其中最直观的是使用 boolean indexing 。
上面的语句只是将一个包含 True/False 对象的 Series 传递给 DataFrame,返回所有 True 的行。
If/then 逻辑#
假设我们想创建一个 bucket 列,其值根据 total_bill 是否小于 10 美元而为 low 或 high。
在电子表格中,逻辑比较可以使用 conditional formulas 来完成。我们将使用公式 =IF(A2 < 10, "low", "high"),然后将其拖到新 bucket 列的所有单元格中。

在 pandas 中,可以使用来自 numpy 的 where 方法完成相同的操作。
日期功能#
本节将提到“日期”,但时间戳的处理方式类似。
我们可以将日期功能分为两部分:解析和输出。在电子表格中,日期值通常会自动解析,但如果你需要,也有一个 DATEVALUE 函数。在 pandas 中,你需要显式地将纯文本转换为 datetime 对象,可以在 while reading from a CSV 或 once in a DataFrame 进行转换。
解析后,电子表格会显示默认格式的日期,但 the format can be changed 。在 pandas 中,通常需要保留日期为 datetime 对象,以便进行计算。在电子表格中,通过 date functions 来输出日期的*部分*(例如年份),而在 pandas 中,则通过 datetime properties 来实现。
给定电子表格 A 列和 B 列中的 date1 和 date2,你可能会有以下公式:
column |
公式 |
|---|---|
|
|
|
|
|
|
|
|
下面展示了等效的 pandas 操作。
更多详情请参阅 时间序列/日期功能 。
选择列#
在电子表格中,可以通过以下方式选择要操作的列:
从一个工作表 Referencing a range 到另一个工作表
由于电子表格列通常 named in a header row ,因此重命名列只需更改该第一个单元格中的文本即可。
下面在 pandas 中显示了相同的操作。
保留特定列#
删除列#
重命名列#
按值排序#
在电子表格中,通过 the sort dialog 来完成排序。
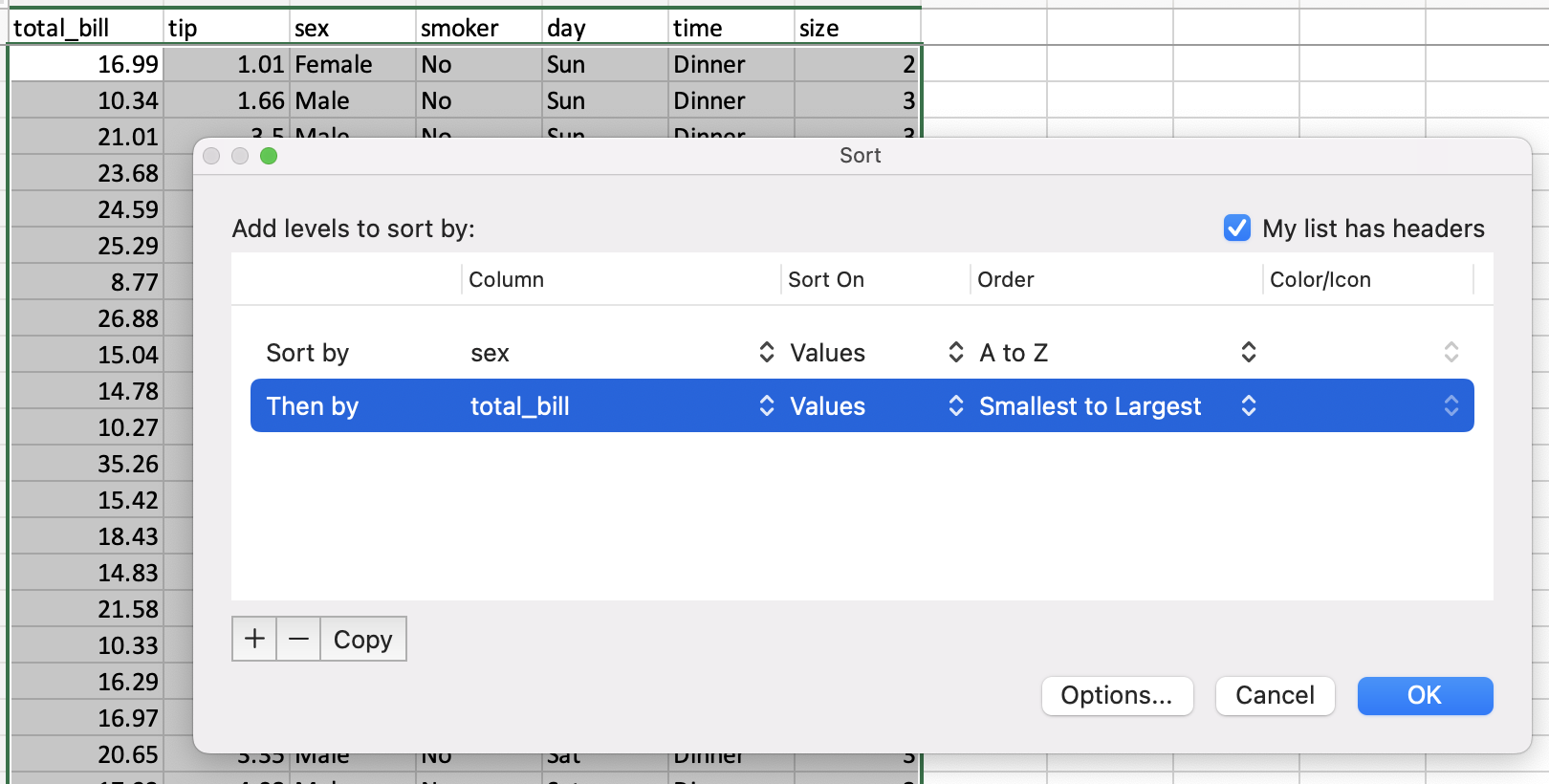
pandas 有一个 DataFrame.sort_values() 方法,它接受一个要排序的列列表。
字符串处理#
查找字符串长度#
在电子表格中,可以使用 LEN 函数查找文本中的字符数。可以结合 TRIM 函数来删除多余的空格。
=LEN(TRIM(A2))
您可以使用 Series.str.len() 查找字符串的长度。在 Python 3 中,所有字符串都是 Unicode 字符串。len 包含尾随空格。使用 len 和 rstrip 来排除尾随空格。
请注意,这仍然会包含字符串内的多个空格,因此不是 100% 等效。
查找子字符串位置#
电子表格的 FIND 函数返回子字符串的位置,第一个字符的位置为 1。
您可以使用 Series.str.find() 方法查找字符串列中字符的位置。find 搜索子字符串的第一个位置。如果找到子字符串,则返回其位置。如果未找到,则返回 -1。请记住,Python 索引是从零开始的。
按位置提取子字符串#
电子表格提供了 MID 公式,用于从指定位置提取子字符串。要获取第一个字符:
=MID(A2,1,1)
使用 pandas,您可以使用 [] 符号通过位置从字符串中提取子字符串。请记住,Python 索引是从零开始的。
提取第 n 个单词#
在 Excel 中,可以使用 Text to Columns Wizard 来分割文本并检索特定列。(请注意,it’s possible to do so through a formula as well 。)
在 pandas 中提取单词的最简单方法是按空格分割字符串,然后按索引引用单词。请注意,如果您需要更强大的方法,还有其他方法。
更改大小写#
电子表格分别提供了 UPPER, LOWER, and PROPER functions ,用于将文本转换为大写、小写和首字母大写形式。
等效的 pandas 方法是 Series.str.upper() 、Series.str.lower() 和 Series.str.title() 。
合并#
以下表将用于合并示例:
在 Excel 中,可以通过 merging of tables can be done through a VLOOKUP 来合并表格。
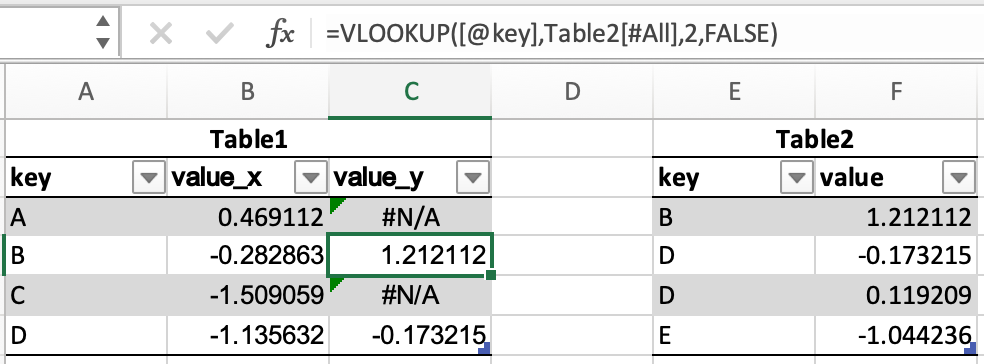
pandas DataFrames 有一个 merge() 方法,它提供了类似的功能。数据不必提前排序,并且可以通过 how 关键字来实现不同的连接类型。
与 VLOOKUP 相比,merge 具有多项优势:
查找值不必是查找表的第一列
如果匹配到多行,将会为每次匹配都生成一行,而不仅仅是第一次匹配
它将包含查找表的所有列,而不仅仅是单个指定的列
其他注意事项#
填充柄#
在一组单元格中创建遵循设定模式的数字序列。在电子表格中,这可以通过输入第一个数字后按住 Shift 键拖动,或者输入前两三个值然后拖动来完成。
这可以通过创建序列并将其分配给所需的单元格来实现。
删除重复项#
Excel 具有内置的 removing duplicate values 。在 pandas 中,这可以通过 drop_duplicates() 来支持。
数据透视表#
电子表格中的 PivotTables 可以通过 重塑和透视表 在 pandas 中复制。再次使用 tips 数据集,让我们按聚会规模和服务员性别查找平均小费。
在 Excel 中,我们使用以下数据透视表配置:
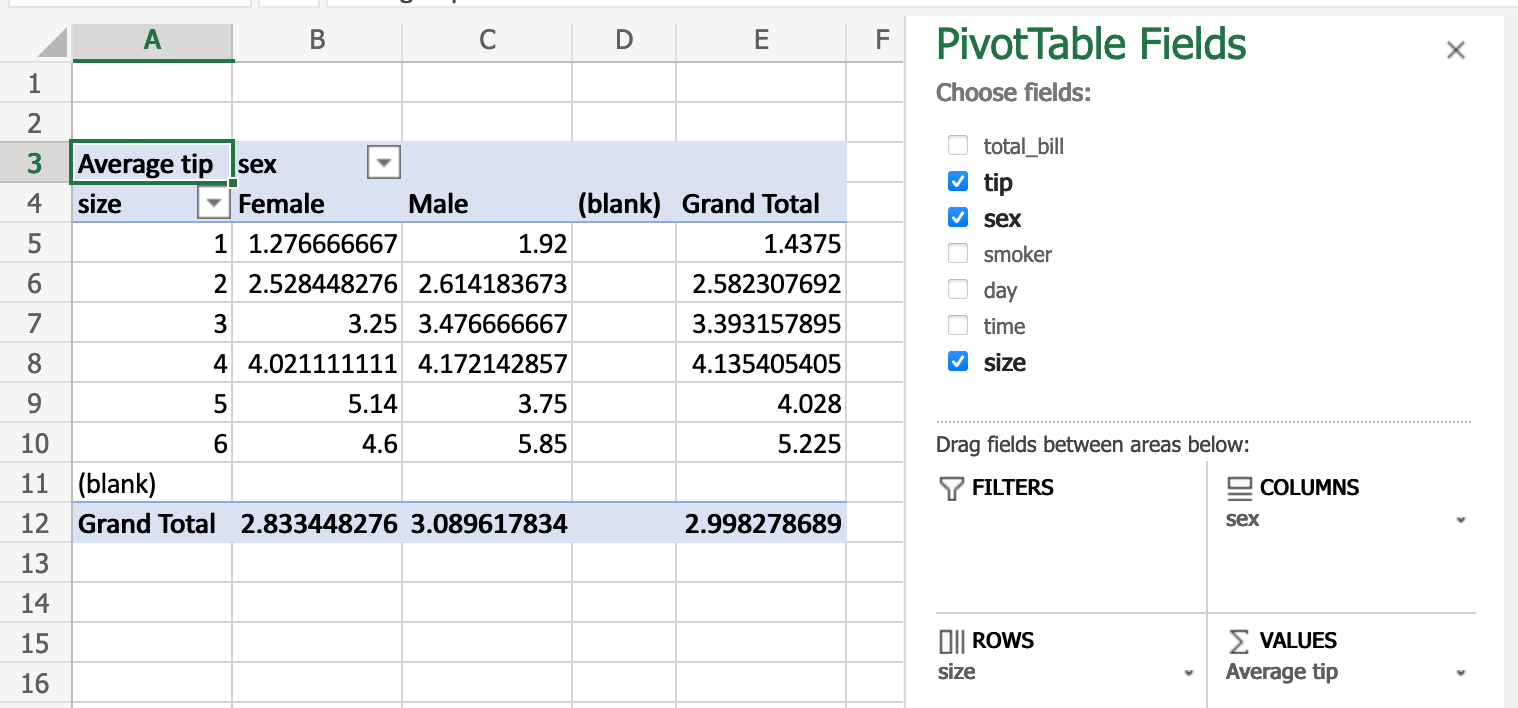
在 pandas 中的等效操作:
添加一行#
假设我们使用的是 RangeIndex (编号为 0、1 等),我们可以使用 concat() 将一行添加到 DataFrame 的底部。
查找和替换#
Excel’s Find dialog 会逐个转到匹配的单元格。在 pandas 中,此操作通常是通过 conditional expressions 对整个列或 DataFrame 一次性完成的。
pandas 的 replace() 方法可以与 Excel 的 全部替换 相媲美。